本文共 987 字,大约阅读时间需要 3 分钟。
前几天给大家分享了网络爬虫中深度优先算法的介绍及其代码实现过程,没来得及上车的小伙伴们可以戳这篇文章——。今天小编给大家分享网络爬虫中广度优先算法的介绍及其代码实现过程。
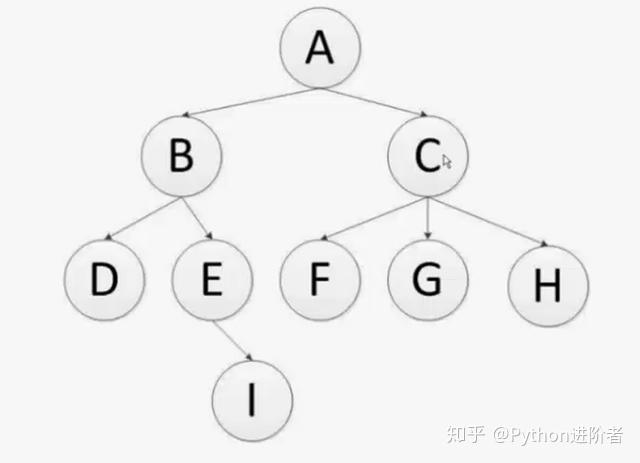
广度优先算法和深度优先算法恰好相反,这里继续以上图的二叉树为例。广度优先算法的主要思想是首先从顶级域名A开始,之后从中提取出两个链接B和C,待链接B抓取完成之后,下一个要抓取的链接则是链接B的同级兄弟链接C,而不是说抓取完成链接B之后,立马往下去抓取子链接C或D。待C抓取完成之后,再返回去继续抓取兄弟链接B下的子链接D或者E,尔后再返回去抓取C链接下的兄弟链接F、G、H,以此类推。
从面上看去,广度优先算法是一种以分层的方式进行抓取的策略。首先将第一层的节点抓取完成,尔后抓取第二层的节点,再是依次抓取第三层的节点,以此类推,直到抓取完毕或者达到既定的抓取条件为止。可以认为广度优先算法是一种按照层次的方法进行遍历,所以也被称为宽度优先算法。理解好广度优先算法之后,再来看上图,可以得到该二叉树呈现的爬虫抓取链接的顺序依次为:A、B、C、D、E、F、G、H 、I(这里假设左边的链接先会被爬取)。通过上面的理解,我们可以认为到广度优先算法本质上是通过队列的方式来进行实现的。

下图展示的是广度优先算法的代码实现过程。
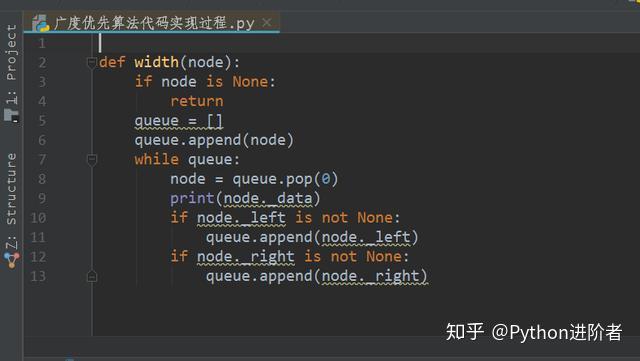
最开始传入一个顶节点node(链接A),然后判断节点是否非空,如果为空,则返回,反之非空的话,则将其放入到一个队列列表中,然后开始进行循环。对队列列表中的元素(此时只有节点A)使用pop()方法将其进行取出,然后将该节点的数据进行打印。将节点打印完成之后,看看其是否存在左节点(链接B)和右节点(链接C),如果左节点非空的话,则得到新的左节点(链接B),将其放入到队列列表中去。尔后程序继续往下执行,右节点的实现过程亦是如此,此时将得到右节点(链接C),将其也放入到队列列表中去。此时队列列表中的元素有链接B和链接C,之后再次进行新一轮的循环。通过这种方式,我们便实现了广度优先算法中的分层抓取链接的过程。这个逻辑相对于深度优先算法来说,更为简单。

深度优先算法和广度优先算法是数据结构里边非常重要的一种算法结构,也是非常常用的一种算法,而且在面试过程中也是非常常见的一道面试题,所以建议大家都需要掌握它。

关于网络爬虫中广度优先算法的简单介绍就到这里了,小伙伴们get到木有咧?
转载地址:http://bubxa.baihongyu.com/